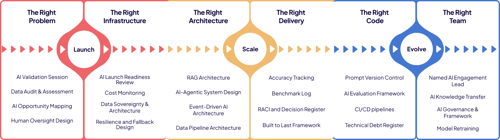

What you walk away with
A production-ready mobile app that's engineered for real-world use: clearly designed, documented, tested, and supported with the operational foundations needed to maintain and improve it over time.
Instead of being left with "something that works", you're left with a product your team can confidently evolve.
"I knew AI was relevant but had no idea where to start or what was actually feasible. The Discovery Session was the most useful hour I'd spent on this topic. They told us which ideas had legs and which to park. No hype. No pitch."
Head of Digital Transformation · Financial Services · Melbourne


