"Before EB Pearls, we were doing manual deployments to production. It was terrifying. Now we deploy 20 times a day with complete confidence. The pipeline they built is rock solid."
— CTO · HealthTech SaaS · Sydney
Discovery Sprint To Production Confidence. Here's Exactly How.
No audit skipped. No big-bang releases. No tribal knowledge that walks out the door. Here is the complete delivery process — across all four engagement types.
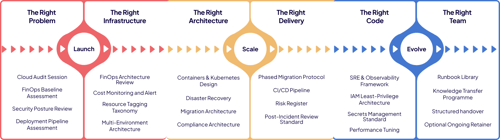
How We Work Together Regardless Of Where You're Starting.
WHAT WE HANDLE
We own the technical delivery: discovery and audit, architecture design and approval, IaC development, CI/CD pipeline build, security gate configuration, observability setup, FinOps controls, DR planning and testing, knowledge transfer, runbook documentation, and post-engagement support. Every technical decision is documented and approved before it's implemented.
WHAT WE NEED FROM YOU
We need access to the right people and systems: engineering lead availability for discovery and milestone reviews, access to existing infrastructure (read-only initially), cloud account access scoped appropriately, and timely sign-off on the target architecture and cost model before build begins. Your decisions at discovery determine 80% of the outcome.
How We Communicate Throughout The Project
One of the most common frustrations teams have is not knowing what’s happening. We prevent that with a consistent communication cadence built into every engagement, so you always know where things stand and what’s next.
Weekly
We + you
Sprint progress, blockers, infrastructure decisions, and anything that needs your sign-off before the next sprint begins.
Per milestone
We + you
Proposed changes reviewed with your engineering lead before any resource is provisioned. Nothing gets built without approval.
Monthly
We + you
FinOps & SRE review
Cloud cost trending, SLO performance, incident review, capacity planning, and architecture decisions.
At handover
We + you
Knowledge transfer
Runbook walkthroughs, IaC code review with your team, architecture documentation handover, and on-call setup.
STARTUP
From Manual Deploys To 20× A Day With Confidence.
The product is growing. Deployments are taking all day. Engineers are scared to push on Fridays. You know this isn't sustainable but you don't have the DevOps expertise in-house to fix it properly.
We build your CI/CD pipeline, cloud infrastructure, and IaC foundations from scratch — with security gates, cost monitoring, and observability configured before the first workload goes live. Three weeks to your first automated pipeline.

The most expensive DevOps engagements are the ones that skip discovery. We map your current infrastructure, deployment processes, cloud costs, and security posture before recommending anything. The written assessment tells you exactly what's wrong, in what priority order, and what fixing it will cost — before you commit to the next step.
| Who | What |
|---|---|
| We | Audit your current deployment process end-to-end: how code goes from commit to production and every manual step in between |
| We | Analyse cloud costs — identify waste, rightsizing opportunities, and untagged resources creating billing blind spots |
| We | Review security posture: IAM permissions, secrets management, network ACLs, encryption at rest and in transit |
| We | Deliver a written assessment: what's wrong, priority order, recommended architecture, and a cost model for the engagement |
| We + You | Discovery call with your engineering lead — align on priorities, constraints, and what "done" looks like before build begins |
| You | Provide read-only cloud account access, repository access, and 2–3 hours of your engineering lead's time during the sprint |
We propose the target architecture with a detailed cost model — you know exactly what you're getting and what it costs before any work begins. The architecture document includes a risk register, a phased delivery plan, and the IaC blueprint reviewed before the first Terraform plan is run.
| Who | What |
|---|---|
| We | Design the target architecture covering compute, networking, storage, security, and observability layers |
| We | Produce a detailed cost model: monthly cloud spend at each phase, reserved instance recommendations, and projected cost after FinOps optimisation |
| We | Write the IaC blueprint in Terraform — module structure, state management approach, and naming conventions documented before coding begins |
| We | Create the risk register: what could go wrong, likelihood, impact, and mitigation plan for each item |
| We + You | Architecture review session — you approve the design and cost model before any resource is provisioned |
| You | Provide written sign-off on the approved architecture before build begins — nothing gets built without your explicit approval |
The CI/CD pipeline ships with security gates included — not as a phase two. SAST, dependency scanning, and automated testing are configured before the pipeline is handed to your team. A staging environment that mirrors production means you can test before you ship — every time.
| Who | What |
|---|---|
| We | Build the CI pipeline: automated build, test, security scan, and artefact publishing on every pull request and main branch commit |
| We | Build the CD pipeline: automated deployment to staging on merge, manual promotion gate to production, rollback trigger on health check failure |
| We | Configure staging environment as a production mirror — same infrastructure, same security controls, same networking — so what works in staging ships cleanly |
| We | Set up branch protection rules, required status checks, and code owner approval gates — so nothing reaches main without passing the full pipeline |
| We + You | Pipeline demo with your engineering team before handover — every gate, every trigger, and every rollback path demonstrated and documented |
| You | Provide access to your source repository and participate in the pipeline walkthrough before it goes live |
Every infrastructure resource is defined in Terraform from the first day of build. No console clicks that aren't tracked. No "I know how to recreate this" single points of failure. The DR plan is written and tested — not just documented — before the first production workload goes live.
| Who | What |
|---|---|
| We | Build all infrastructure in Terraform: VPC, subnets, security groups, compute (EKS/ECS/EC2), databases, storage, load balancers, and DNS |
| We | Configure IAM with least-privilege from the first environment — no wildcard permissions, no long-lived access keys in application code |
| We | Set up Secrets Manager (or Vault) for all credentials — no hardcoded secrets, no environment variables containing sensitive values |
| We | Write and test the DR plan: backup frequency, recovery time objective, recovery point objective, and a tested restore procedure before go-live |
| We | Configure FinOps controls: resource tagging strategy, AWS Budgets alerts, Cost Explorer dashboards, and rightsizing recommendations |
| We + You | Code review sessions with your engineering team as Terraform modules are built — so your team understands the IaC before it's handed over |
Monitoring is configured before the first user arrives — not as a post-launch task. SLOs are defined, error budgets established, and PagerDuty on-call routing set up. You know about incidents before your users do from day one in production.
| Who | What |
|---|---|
| We | Configure application and infrastructure monitoring: metrics, logs, traces, and dashboards covering all critical services |
| We | Define SLOs with your engineering lead — availability, latency, error rate — and establish error budgets that determine when to prioritise reliability over features |
| We | Set up alerting thresholds, on-call routing in PagerDuty, and runbook links on every alert so responders know what to do when they get paged |
| We | Run a pre-launch load test: confirm the system behaves as designed under production-level traffic before real users arrive |
| We + You | On-call handover session — your engineering team walks the dashboards, alert policies, and on-call runbooks before go-live is approved |
Our goal is your independence. Every engagement ends with a team that can operate without us. Runbooks written for every deployment and incident type, architecture diagrams updated to reflect the live system, and IaC code reviewed with your engineers so they understand what they're inheriting.
| Who | What |
|---|---|
| We | Write operational runbooks for every deployment, rollback, incident response, and routine maintenance procedure |
| We | Produce updated architecture diagrams reflecting the live system — not the original design document |
| We | Run IaC code review sessions with your engineers: module by module, how each resource is defined, and how to make changes safely |
| We | Confirm all accounts, repos, Terraform state, and credentials are fully in your control — no EB Pearls access required to operate |
| We + You | Handover sign-off: your engineering lead confirms they can operate, modify, and extend the infrastructure without assistance before the engagement closes |
| You | Optional: engage EB Pearls on a monthly retainer for ongoing monitoring, patching, incident response, and architectural guidance |
Typical Startup Engagement Timeline
Discovery sprint
1-2 Weeks
Architecture design
1 Week
CI/CD pipeline
3-4 Weeks
Cloud infrastructure
4-8 Weeks
Observability & go-live
1-2 Weeks
Knowledge transfer
1 Week
Book A Free CI/CD Audit
We'll map your current deployment process, identify the biggest risks, and tell you what a production-grade pipeline will cost — before you commit anything.
ENTERPRISE
Modernise What's There. Without Breaking What's Running.
You've got complexity. Multiple teams, multiple environments, legacy systems that can't go down. A full rebuild isn't possible. Every change is risky. Every release is a process. Compliance requirements are getting stricter every year.
We audit what exists before touching anything, phase every modernisation step, and wrap your existing infrastructure in IaC gradually — so you get the benefits of modern DevOps without the risk of a big-bang rewrite.

Enterprise modernisation starts with a thorough audit of what exists. No changes are made to the live system during discovery. We document every pipeline, every deployment process, every manual step, every compliance control gap — and every risk that sitting still is creating.
| Who | What |
|---|---|
| We | Produce a full infrastructure inventory: every service, every environment, every dependency, and every deployment process currently in use |
| We | Assess security posture against OWASP, CIS benchmarks, and your relevant compliance framework (SOC 2, HIPAA, PCI DSS, ISO 27001) |
| We | Identify IaC coverage gaps: what is and isn't managed in Terraform or CloudFormation — and the risk each unmanaged resource creates |
| We | Deliver a prioritised remediation roadmap: what to fix first, what can wait, and what the risk of deferral is for each item |
| We + You | Walkthrough of audit findings with your engineering lead and compliance stakeholders before any remediation begins |
| You | Provide read-only access to existing infrastructure and pipelines, and nominate a technical stakeholder who understands the system history |
Enterprise modernisation cannot be a single big-bang project. We design a phased plan where each phase delivers value independently, has a tested rollback path, and doesn't put the live system at risk. Every phase requires your explicit approval before it begins.
| Who | What |
|---|---|
| We | Design the phased modernisation plan: logical grouping of changes, dependency ordering, parallel run periods, and a rollback plan for each phase |
| We | Sequence changes to protect stability: IaC wrapping of existing resources first, then pipeline improvements, then security gate insertion, then new capability |
| We | Produce a compliance remediation plan: which gaps are addressed in which phase, and what evidence each remediation produces for audit purposes |
| We + You | Phase plan approval with your CTO, engineering lead, and compliance stakeholders before any change touches the live environment |
We don't require a full rebuild to get your infrastructure into IaC. We use Terraform import to bring existing resources under code management without recreating them — giving you the auditability and reproducibility of IaC with minimal risk to the live system.
| Who | What |
|---|---|
| We | Import existing resources into Terraform state systematically — starting with highest-risk, most-frequently-changed resources |
| We | Configure drift detection: automated checks that alert when anyone makes a console change that diverges from the Terraform state |
| We | Refactor existing IaC (if any) into reusable modules — applying consistent naming conventions, tagging strategy, and documentation standards |
| We | Enforce a Git-first change process: all infrastructure changes through PR, reviewed, and applied via CI/CD — no console modifications without corresponding code change |
| We + You | IaC code reviews with your engineering team as modules are built — knowledge transfer happens during build, not at handover |
Compliance controls retrofitted after launch are incomplete and expensive. We implement compliance as code — policy guardrails in OPA or AWS SCPs, automated evidence collection, and a full audit trail — so your next compliance review is a formality, not a scramble.
Compliance as code: OPA policies enforced in CI/CD (e.g. no public S3 buckets, no unencrypted EBS volumes, no wildcard IAM), AWS Config rules with automatic remediation, and CloudTrail audit logging configured for every account. Evidence collection automated for SOC 2, HIPAA, or PCI DSS reviews.
| Who | What |
|---|---|
| We | Insert security gates into existing CI/CD pipelines: SAST, dependency scanning, container image scanning, and secrets detection on every build |
| We | Implement policy guardrails using OPA or AWS Service Control Policies — preventing non-compliant resources from being created at all |
| We | Configure automated compliance evidence collection: logs, configuration snapshots, and change records formatted for your specific audit framework |
| We + You | Compliance review session with your security and legal team — confirming controls meet your audit requirements before the engagement closes |
"We had an existing product, internal stakeholders, and a lot of complexity. EB Pearls helped us improve what was already there without disrupting the business — they even came in to view our processes in person. The engagement felt structured from day one."
— Michael Hanna · Digital Transformation Lead · Bingo Industries
Book A Free Infrastructure Audit
We'll map your current state, identify the highest-risk gaps, and recommend a phased modernisation path that doesn't disrupt what's running.
MIGRATION
Hard Deadline. Can't Afford Downtime. 20+ Migrations. Zero Unplanned Outages.
Cloud migrations are high-stakes. Your data centre lease is ending, or you're on the wrong cloud, or your on-premises infrastructure is failing to scale. Either way, you have a hard deadline and can't afford a botched cutover.
The biggest migration risks aren't technical — they're around planning, sequencing, rollback readiness, and compliance. We've executed over 20 Australian cloud migrations without a single hour of unplanned downtime. The process is why.
The biggest migration failures start with moving workloads before understanding their dependencies. We assess every application, its dependencies, its data flows, its compliance requirements, and its migration risk before recommending a sequencing approach or a timeline.
| Who | What |
|---|---|
| We | Produce a complete workload inventory: every application, its dependencies, its data flows, its current SLAs, and its migration complexity rating |
| We | Map application dependencies — identify the workloads that must move together versus those that can move independently |
| We+You | Assess compliance requirements for each workload: data sovereignty, encryption requirements, audit log retention, and access control standards |
| We | Produce the migration risk register: for each workload, what could go wrong, the impact, and the mitigation or rollback approach |
| We + You | Readiness review with your CTO, operations lead, and compliance stakeholders before migration sequencing is agreed |
| You | Nominate a technical stakeholder with knowledge of the existing system history — the person who knows where the bodies are buried |
The migration plan sequences workloads into waves based on dependency order and risk — not deadline pressure. Each wave has a parallel run period, a tested rollback path, and explicit go/no-go criteria. We never move a workload without a tested rollback available.
| Who | What |
|---|---|
| We | Design the target cloud architecture: networking, compute, database, storage, security, and observability for the migrated environment |
| We | Sequence workloads into migration waves based on dependency order, risk rating, and your operational constraints |
| We | Define the parallel run period for each wave: how long both environments run simultaneously, what data sync validation looks like, and what the cutover trigger is |
| We | Document and rehearse the rollback procedure for each wave — if the cutover goes wrong, we know exactly how to reverse it and how long it takes |
| We + You | Migration plan sign-off before any workload moves — your explicit approval is required for each wave's go-ahead |
Each migration wave runs with both environments active simultaneously for a defined parallel run period. Traffic is only cut over when health checks are passing, data sync is validated, and the rollback has been tested. No workload is a one-way door.
| Who | What |
|---|---|
| We | Execute lift-and-shift for applicable workloads using AWS MGN, Azure Migrate, or equivalent — minimising downtime during the initial move |
| We | Migrate databases using AWS DMS or equivalent with continuous replication — so the source database remains the source of truth until cutover is confirmed |
| We | Validate data sync integrity at each parallel run checkpoint before approving cutover — row counts, checksums, and application-level smoke tests |
| We | Execute blue/green DNS cutover with a defined rollback window — new environment receives traffic, old environment remains live for the rollback period |
| We + You | Go/no-go call for each wave cutover — explicit sign-off from your operations lead based on the agreed health check criteria |
Lift-and-shift gets you to the cloud. The post-migration phase makes it cloud-native. We rebuild the migrated infrastructure in Terraform, optimise for cloud-native services, configure observability, implement FinOps controls, and produce the compliance documentation for your first cloud audit.
| Who | What |
|---|---|
| We | Rebuild all migrated infrastructure in Terraform — replacing console-managed resources with version-controlled IaC |
| We | Optimise for cloud-native services where applicable: managed databases, serverless functions, managed container services — replacing lift-and-shifted VMs with purpose-built cloud services |
| We | Implement FinOps controls: resource tagging, budget alerts, rightsizing recommendations, and reserved instance planning for the new environment |
| We | Produce compliance documentation: architecture diagrams, security control evidence, and audit trail exports formatted for your compliance framework |
| We + You | Compliance review support — we attend your first post-migration compliance review and answer auditor questions about the new environment |
"We had a major data centre migration with a hard deadline. EB Pearls came in, built the plan, and executed it flawlessly. Not a single hour of unplanned downtime. Genuinely impressed."
— CIO · Logistics Enterprise · Brisbane
Book A Migration Assessment
Tell us your deadline and your current environment. We'll assess migration readiness, recommend a sequencing approach, and give you an honest cost and timeline.
AUGMENTATION
The Specialist You Need, For Exactly As Long As You Need Them.
Sometimes you don't need a full team. You need a senior AWS architect for the next 12 weeks, or a Kubernetes specialist to get your cluster production-ready, or someone to review your IaC and tell you what's wrong. You want the expertise for a defined scope — and you want your team to own it at the end.
Knowledge transfer is built into every augmentation engagement from day one — not as a retrospective handover. Your team learns as we build. The goal is your independence, not a permanent dependency on EB Pearls.

We need to understand what you're trying to achieve, what your team currently knows, and what specialist capability is missing before we recommend who to embed. The scoping call produces a defined scope, a recommended specialist profile, an engagement model (project-based, retainer, or embedded), and a knowledge transfer plan — before any contract is signed.
| Who | What |
|---|---|
| We | Map your team's current capability against the gap you're trying to fill — recommending the right seniority and specialism, not the most billable option |
| We | Define the engagement scope: what will be built, what will be reviewed, and what knowledge transfer outcomes are expected by the end |
| We | Recommend the engagement model: project-based with a defined deliverable, time-and-materials retainer, or embedded specialist in your team's sprint cycle |
| We + You | Agree on the knowledge transfer plan — what your team should be able to do independently by the time the engagement ends |
| You | Share your team's current capability level honestly — the knowledge transfer plan only works if we know the right starting point |
Knowledge transfer built into the engagement from day one means your team learns as the specialist works — not from a handover document they receive at the end and have to decode alone. Every architecture decision is explained and documented. Every code review is a teaching moment.
| Who | What |
|---|---|
| We | Work in your tools, your sprint cadence, and your code review process — integrating with your team, not running a parallel workstream |
| We | Document every architecture decision with rationale — your team understands not just what was built but why each approach was chosen |
| We | Run weekly architecture review sessions with your engineers — covering what was built, how it works, and how to extend it |
| We | Review your existing IaC and flag risks, anti-patterns, and improvement opportunities — your team learns from the review, not just the outcome |
| We + You | Fortnightly knowledge transfer check-in — your engineering lead confirms the transfer is on track for the agreed outcomes |
| You | Allocate your engineers' time to participate in code reviews, architecture sessions, and pairing — the knowledge transfer only works if your team shows up |
The engagement doesn't close until your team demonstrates independence on the work delivered. Runbooks are written for every operational procedure. Architecture documentation is updated to reflect the live system. Your engineering lead confirms they can maintain, extend, and troubleshoot without assistance.
| Who | What |
|---|---|
| We | Write operational runbooks for every deployment, incident response, and routine maintenance task the specialist handled |
| We | Produce updated architecture documentation reflecting the live system — diagrams, decision records, and component descriptions |
| We | Run a final IaC code walkthrough with your engineering team: every module, every resource, and every configuration explained |
| We | Confirm all accounts, repos, and credentials are fully in your control — no ongoing access required from EB Pearls |
| We + You | Independence verification: your engineering lead walks through a scenario (e.g. "add a new microservice") and confirms they can do it without assistance — before handover is accepted |
| You | Optional: engage EB Pearls on a lightweight retainer for architecture reviews, incident escalation support, or future specialist needs |
"What stood out straight away was how clear they were on scope and cost. We understood exactly what was included — and there were no hidden extras later. More importantly, our team actually knows how to operate what they built."
— Engineering Lead · FinTech · Sydney
Discuss Your Augmentation Need
Tell us what specialist expertise you need and for how long. We'll recommend the right profile, engagement model, and knowledge transfer plan before you commit.
Still Have Questions?
A 60-minute cloud audit answers most of them — including an honest assessment of your current infrastructure and what the right next step is. Free, no obligation.
A CI/CD pipeline from scratch takes 3–5 weeks. A full cloud infrastructure build runs 8–12 weeks. A cloud migration depends on workload complexity and the number of applications — we provide a detailed wave plan with timelines after the readiness assessment. Enterprise modernisation is phased across 3–9 months depending on scope. Every engagement starts with a 1–2 week discovery sprint that produces a realistic timeline before you commit to the full engagement.
Yes. EB Pearls is an AWS Consulting Partner with certified Solutions Architects and DevOps Professional engineers. We also have Azure-certified and GCP-certified engineers. For multi-cloud or cross-cloud migration engagements, we can staff appropriately across all three. Cloud provider recommendation is always based on your workload characteristics and existing investment — not on our partner margins.
Yes. Compliance as code is a core part of our DevSecOps delivery. We implement compliance controls into the CI/CD pipeline and infrastructure — OPA policies, AWS Config rules, CloudTrail logging, and automated evidence collection — formatted for the specific audit framework you're targeting. For migration clients, we produce compliance documentation ready for your first cloud audit and will attend the review session to answer auditor questions about the new environment.
We never cut over to a new environment without a tested rollback available. Every migration wave has: a defined parallel run period where both environments are active, health checks that must be passing before cutover is approved, a tested rollback procedure with a documented time-to-revert, and explicit go/no-go criteria that your operations lead signs off on. In 20+ migrations, we've never needed an unplanned rollback — because the planning prevents the situations that require one.
You do. 100%. All Git repositories, Terraform state, cloud accounts, access credentials, and documentation belong to you from day one. Written into every contract without exception. We never resell cloud or mark up your cloud bill. You can take it to another team, hand it to an internal developer, or continue with EB Pearls. The goal of every engagement is your independence — not a permanent dependency on us.
FinOps controls are standard across every engagement — not an add-on. This includes a tagging strategy, AWS Budgets alerts, Cost Explorer dashboards, rightsizing recommendations, and reserved instance planning. On brownfield engagements where infrastructure has grown organically, we typically achieve 30–50% cost reduction. The 41% average we quote is from real client data. We provide a cost model before the engagement begins so you know the projected savings before committing.
That's a legitimate scope. Architecture reviews, IaC code audits, security posture assessments, and pipeline reviews are all discrete deliverables we provide without a full engagement. The free cloud audit is the entry point — from there, the scope can be as targeted as a single service review or as broad as a full infrastructure modernisation. We'd rather do a $5k review that saves you from a $200k mistake than sell you an engagement you don't need.
Yes — as an optional retainer, never as a dependency. We offer monthly retainers covering ongoing monitoring, patching, incident response escalation, cost optimisation reviews, and architectural guidance. The retainer is available for teams who want continued support — but it's never a requirement. The goal of every engagement is a team that can operate independently. If you want an optional safety net on top of that, the retainer is the right model.
1
Your Information
2
Book Meeting
3
Confirmation
Not Sure Which Path Fits?
A free discovery call will give you clarity in under an hour. No pressure — just a straight conversation with a team that's done this 900+ times.

What to expect on your call
What to expect
-
1
Share a few details
Complete the form with your contact details and what you need help with. -
2
Book your free discovery call
Once you submit the form, choose a time that suits you for your discovery call. -
3
Privacy comes first
Sign an optional NDA to ensure the highest privacy level and protection of your idea. -
4
Discovery call
We’ll discuss your goals, the support you need and answer your questions. If we’re a good fit, we’ll outline the next steps.
What to expect
-
1
Share a few details
Complete the form with your contact details and what you need help with. -
2
Book your free discovery call
Once you submit the form, choose a time that suits you for your discovery call. -
3
Privacy comes first
Sign an optional NDA to ensure the highest privacy level and protection of your idea. -
4
Discovery call
We’ll discuss your goals, the support you need and answer your questions. If we’re a good fit, we’ll outline the next steps.